Levenshtein distance?#
문자열 비교 알고리즘으로, 문자열 a,b가 있을 때 a를b로 만드는데 드는 비용을 동적 계획법으로 구하는 알고리즘 문자열의 유사성을 판단하는데 쓰인다.
기본 풀이#
dp[i][j] = 문자열 a의 [i]까지 고려했을때, 문자열 b의[j]를 만들 수 있는 최소 변환 수
- 문자열은 빈 문자열
''부터 시작한다. 빈 문자열은 다른 문자열의 길이만큼 특정 문자를 추가해야 같아지므로 각각 인덱스값을 가지게 된다.
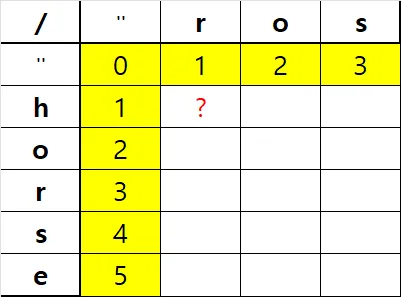
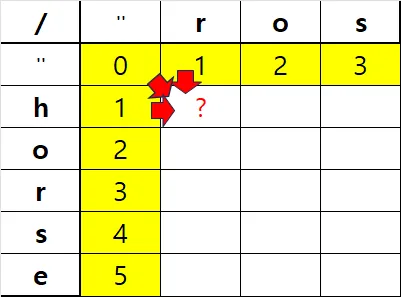
dp[1][1]은 세 가지 중 하나로 만들어지는데
- dp[0][1](빈 문자열에서 r을 만듬)에서
h를 삭제 - dp[1][0](h를 빈 문자열로 만듬)에서
r을 추가 - dp[-1][-1](빈 문자열)에서 이번에 추가된
h를r로 교체 만일 word1[i]==word2[j]일 경우, 교체비용은 0
이중 최적의 경우 + 해당 문자열을 연산하는 비용(1) 이다. 만일 i번째 문자열이 j번째 문자열과 같다면, 굳이 대체/삭제/추가할 필요가 없이, dp[i-1][j-1]의 결과를 그대로 가져다 쓰면 된다.
점화식#
$$ D[i][j] = \begin{cases} D[i-1][j-1] & \text{if } \text{str1}[i-1] = \text{str2}[j-1] \\ \min(D[i-1][j] + 1, D[i][j-1] + 1, D[i-1][j-1] + 1) & \text{if } \text{str1}[i-1] \neq \text{str2}[j-1] \end{cases} $$결과#
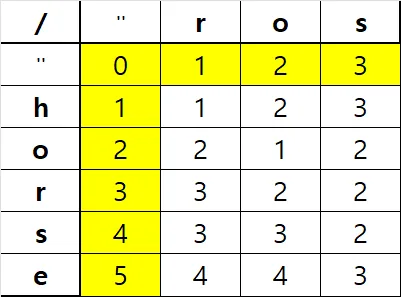
결과는 다음과 같다. 세로 문자열을 최종적으로 가로 문자열로 변환하므로, dp[-1][-1]인 3이 된다.
코드#
기본풀이#
class Solution:
def minDistance(self, word1: str, word2: str) -> int:
n,m = len(word1),len(word2)
dp = [[None] * (m+1) for _ in range(n+1)]
for i in range(n+1):
dp[i][0] = i
for j in range(m+1):
dp[0][j] = j
for i in range(1,n+1):
for j in range(1,m+1):
if word1[i - 1] == word2[j - 1]: # 문자가 같다면
dp[i][j] = dp[i - 1][j - 1] # 대각선 값 그대로 사용
else:
# 문자가 다를 때만 삽입, 삭제, 대체 중 최소값 + 1
dp[i][j] = min(
dp[i - 1][j - 1], # 대체
dp[i - 1][j], # 삭제
dp[i][j - 1] # 삽입
) + 1
return (dp[-1][-1])메모리 효율 개선#
class Solution:
def minDistance(self, word1: str, word2: str) -> int:
n,m = len(word1),len(word2)
dp = [i for i in range(m+1)]
tmp = [-1] + [0]*m
for i in range(1,n+1):
tmp[0] = i
for j in range(1,m+1):
if word1[i-1] == word2[j-1]:
tmp[j] = dp[j-1]
else:
tmp[j] = min(
dp[j-1],
dp[j],
tmp[j-1],
)+1
for k in range(m+1) :
dp[k] = tmp[k]
return dp[-1]재귀#
class Solution:
def minDistance(self, word1: str, word2: str) -> int:
@cache
def dfs(i, j):
if i == 0:
return j
if j == 0:
return i
if word1[i-1] == word2[j-1]:
return dfs(i-1, j-1)
else:
replace = dfs(i - 1, j -1)
insert = dfs(i, j - 1)
delete = dfs(i - 1, j)
return min(replace, insert, delete) + 1
return dfs(len(word1), len(word2)) bfs(큐)#
class Solution:
def minDistance(self, word1: str, word2: str) -> int:
return self.bfs(word1,word2)
def bfs(self, word1, word2):
m, n = len(word1), len(word2)
q = deque([(0, 0)])
numEdits = 0
visited = set()
while q:
qLen = len(q)
for _ in range(qLen):
i, j = q.popleft()
if (i,j) in visited:
continue
visited.add((i,j))
while i < m and j < n and word1[i] == word2[j]:
i += 1
j += 1